क्या आपने कभी वेब क्रॉलर के बारे में सुना है, यह क्या काम करता है, इंटरनेट की दुनिया में इसका क्या महत्व है? दरअसल, जब हम गूगल या बिंग जैसे सर्च इंजन के माध्यम से कोई जानकारी खोजते हैं तो यह हमारे सामने यूआरएल के रूप में संबंधित जानकारी की एक बड़ी सूची प्रस्तुत करता है।
लेकिन, क्या आपने कभी सोचा कि एक खोज इंजन यह कैसे करता है, खोज इंजन इतनी बड़ी जानकारी कहाँ से और कैसे एकत्रित करता है? यहाँ से वास्तव में, वेब क्रॉलर अस्तित्व में आते हैं।
तो, इस आर्टिकल में हम वेब क्रॉलर के बारे में अधिक विस्तार से जानेंगे साथ ही हम यह भी जानेंगे कि वेब क्रॉलर कैसे काम करता है। तो, हमारे साथ बने रहे ताकी वेब क्रॉलर क्या है इसके बारे मे आपको पुरी जानकारी मिल सके।
Table of Contents
Web Crawler क्या है?
“वेब क्रॉलर्स” जिन्हें अक्सर डिजिटल स्पाइडर या बॉट भी कहा जाता है, जो वर्ल्ड वाइड वेब पर यात्रा करने वाली वेबसाइटों से नया डेटा खोजने और उन्है एकत्रित करने के लिए डिज़ाइन किया गया है? यह किसी भी खोज इंजन का सबसे महत्वपूर्ण हिस्सा है जो खोज इंजन को SERPs में वेब पेजों को ठीक से अनुक्रमित करने में सक्षम बनाता है।
दरअसल, वेब क्रॉलर एक प्रशिक्षित बॉट है जो इंटरनेट पर घूम-घूम कर वेबसाइटों के बारे में जानकारी एकत्रित करता है और उनके बारे मे खोज इंजनोंको सुचित करता है। आप इसे एक रोबोट की तरह भी सोच सकते हैं जो विभिन्न वेबसाइटों के बारे में डेटा इकट्ठा करने के इरादे से हमेशा वेबसाइट का दौरा करता रहता है।
आप इसे एक आभासी मकड़ी की तरह भी सोच सकते हैं, जो हमेशा नई प्रकाशित सामग्री पर ध्यान देता है और उनके बारे मे जानकारी एकत्रित करता है और खोज इंजनों के लिए कड़ी मेहनत करता है।
वेब क्रॉलर कैसे काम करता है?
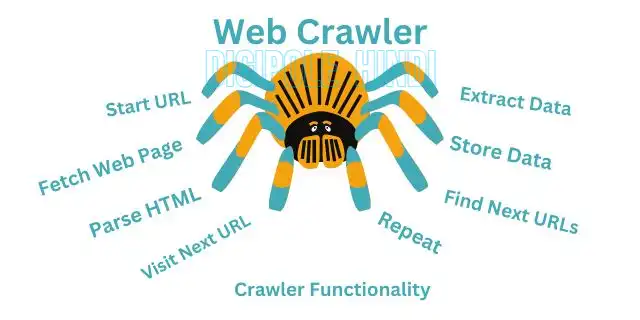
आमतोरपर, वेब क्रॉलर पहचान बाले यूआरएल की सूची को क्रॉलर करते हुये आपना काम शुरू करता हैं।इसके बाद वे उस पेज पर मौजुद दुसरी यूआरएल या हाइपरलिंको को फलौ करता है और डेटा कलेक्ट करते हुये आगे इसी तरह बडता रहता है और उन बैब पैजौ को इन्डेक्स करता है।

ये प्रक्रिया लगातर चलता रहता है। आमतोरपर, वे इन्टेरनेट पर नए पैजो कि खौज करता रहता है साथही इन पैजो के तलास करता है जिनमे कोई बदलाब किया गया हो।
वेब क्रॉलर बॉट का उपयोग करता है जिन्हें आवश्यक डेटाओ को इकट्ठा करने और उनके URLs को index करने के उद्देश्यों से डिजाइन किया गया है। दरसल ये एक pre-designed program है जो एक algorithm को फलौ करते हुे आपना काम करता है।
इस मामले में, वेब क्रॉलर के साथ एक दुसरा algorithm भी साथ-साथ काम करता है जिसे वेब स्क्रैपर कहा जाता है, जो आवश्यक जानकारीओ को डाउनलोड करता है। हलांकी, वेब स्क्रैपिंग और वेब क्रॉलिंग के विच समानता होते हुये भी वे अलग-अलग कामो को अनजाम देता हैं।
स्क्रैपिंग का उद्देश्य किसी वेबसाइट से डेटाओ को पार्स करना और उन्है निकालना है, जबकि वेब क्रॉलिंग का काम यूआरएल की खोज करना है। इस लेख मे आगे हम वेब स्क्रैपिंग और वेब क्रॉलिंग के विच की अंतर को भी समझने की कोशिश करेंगे। वेब क्रॉलर कैसे काम करता है निचे image के द्बारा समझाने का प्रयास किया गया है:
वेब स्क्रैपिंग क्या है?
वेब स्क्रैपिंग किसी वेबसाइट से बड़ी मात्रा में जानकारी एकत्र करने की एक स्वचालित प्रक्रिया है। उनमें से, अधिकांश स्क्रैपिंग डेटा एक असंरचित प्रारूप में एकत्र किया जाता है जिसे बाद में एक स्प्रेडशीट में संरचित रूप में परिवर्तित किया जाता है।
ये स्क्रैपिंग टूल मूल रूप से एक बॉट हैं जिन्हें विशेष रूप से विभिन्न वेबसाइटों से जानकारी निकालने के लिए प्रोग्राम किया गया है। इस उपकरण का उपयोग विभिन्न उद्देश्यों जैसे व्यवसायों के लिए बाजार अनुसंधान, सरकारी सतर्कता आदि के लिए किया जाता है।
वेब क्रॉलिंग और वेब स्क्रैपिंग के बीच क्या अंतर है?
जैसा कि मैंने पहले ही बताया कि, वेब क्रॉलर एक पूर्व-डिज़ाइन प्रोग्राम हैं जो एक algorithm को फलो करते हुये बैवसाइटो से जानकारी लाता हैं और उन्हें क्रमानुसार खोज इंजन परिणाम पृष्ठों पर दिखाने के लिए सहेजते हैं।
दूसरी ओर, वेब स्क्रैपिंग तब होता है जब कोई बॉट बिना किसी पूर्व अनुमति के किसी वेबसाइट पर कुछ सामग्री डाउनलोड करता है। ऐसा अक्सर तब होता है जब जानबूझकर किसी वेबसाइट पर दुर्भावनापूर्ण सामग्री फैलाने के लिए कोई सामग्री या कोड डाला जाता है।
वेब स्क्रैपर बॉट robots.txt के निर्देशों की अवहेलना कर सकता हैं, जबकि दूसरी ओर, वेब क्रॉलर, खोज इंजन की भूमिका का पालन करता है, क्योंकि यह robots.txt फ़ाइल द्वारा नियंत्रित होता है।
Web Crawler के प्रकार
कई प्रकार के बैव क्रॉलर अस्तित्व में हैं और उनमें से हर एक को विशिष्ट अनुप्रयोगों के लिए या विशिष्ट कार्य के लिए डिज़ाइन किया गया है। हालाँकि, प्रत्येक क्रॉलर की तुलना उसके विभिन्न मापदंडों से की जा सकती है। विभिन्न प्रकार के वेब क्रॉलर के बारे में जानने से पहले, उनके 3 मुख्य प्रकारों के बारे में जानना ज़रूरी है:
1. In-house web crawlers: इसे किसी खास मकसत को पुरा करके लिए कंपनी के द्बारा विकसित किया जाता है जैसेकि किसी परियोजना या बैवसाइट की गतिविधि पर नजर रखने के लिए किया जाता है।
2. Public web crawlers: ये सार्वजनिक रुप से इंटरनेट पर निःशुल्क उपलब्ध हैं, और चाहे तो हर कोई इनका उपयोग कर सकता है। Googlebot, Bingbot आदि इस श्रेणी के अंतरगत आता हैं। इसका उपयोग आमतौरपर, खोज इंजन के लिए डेटा इकट्ठा करने और उन्है अनुक्रमण करने के लिए किया जाता है।
3. Niche web crawlers: ये मूल रूप से विशिष्ट सामग्री वाली वेबसाइटों को क्रॉल करने के लिए प्रोग्राम किए गए हैं। जैसे कि नौकरी से संबंधित वेबसाइट, समाचार वेबसाइट और ई-कॉमर्स वैबसाइट आदि।
इनके अलाबा भी कुछ और तरह के web crawler उयलध्ब है जिनके नाम निचे दए गए है:
- Deep Web Crawlers
- Vertical Crawlers
- Archival Crawlers
- Link Checkers
- Distributed Crawlers आदि।
Web Crawler के उदाहरण
यहां आमतौर पर उपयोग किए जाने वाले कुछ वेब क्रॉलर उदाहरण के तौर पर दिए गए हैं जो विभिन्न खोज इंजनों से संबंधित हैं:
- Googlebot
- Bingbot
- Yahoo! Slurp
- YandexBot
- DuckDuckBot
- ExaBot
वेब क्रॉलर SEO को कैसे प्रभावित करता हैं?
जैसा कि हम जानते हैं, SEO सर्च इंजन ऑप्टिमाइजेशन का संक्षिप्त रूप है, जो सर्च इंजन इंडेक्सिंग में एक बड़ी भूमिका निभाता है ताकि एक वेबसाइट सर्च इंजन परिणाम पृष्ठ पर ऊपर दिखाई दे।
यह मेटा विवरण, H1- H2 शीर्षक और स्पाइडर बॉट के माध्यम से प्राप्त वेब पेज के सामग्री कि प्रासंगिकता को समझने के साथ काम करता है। सरल शब्दों में कहा जाए तो, अगर क्रॉलर वेबपेज को बेहतर ढंग से समझता है और robots.txt द्वारा किसी भी प्रतिरोध के बिना अपनी भूमिकाओं का ठीक से पालन करता है, तो संभवतः एक वेबसाइट खोज परिणामो में उच्चतर दिखाई दे।
लेकिन जब robots.txt फ़ाइल के अवरुद्ध होने के कारण स्पाइडर बॉट किसी वेबसाइट को अच्छी तरह से क्रॉल नहीं कर पाते हैं, तो यह अनुक्रमित नहीं होता है, और परिणामस्वरूप, इसे खोज परिणामों में नहीं दिखाया जाएगा।
इसलिए, एक वेबसाइट के मालिक के रूप में, robots.txt फ़ाइल को ठीक से सेट करना सबसे महत्वपूर्ण है ताकि उसे खोज परिणामों से अधिक ऑर्गेनिक ट्रैफ़िक प्राप्त हो सके।
वेब क्रॉलर को स्पाइडर क्यों कहा जाता है?
वेब क्रॉलर जिसे “स्पाइडर” के नाम से भी जाना जाता है क्योंकि यह बिल्कुल असली मकड़ी की तरह व्यवहार करता है। जैसे एक मकड़ी आपने शिकार के लिए जाल बुनता है, कुछ इसी तरह से एक web crawler भी बैवसाइटो पर मौजुद लिंक को पकरने के लिए ऐसा ही एक बातावरण तैयार करता है।
एक मकड़ी जब आपना जाल बुनता है, तो वे पेहले एक रस्ता बनाते है और फिर उसी रस्ते को फलो करते हुये पुरी जाल बुनता है। बिलकुल उसी तरह से, एक वेब क्रॉलर भी पहले एक लिंक को फलौ करते हुये आपना रस्ता बनाता है और आगे बड़ता जाता है।
वेब क्रॉलर का मुख्य उद्देश्य क्या है?
वेब क्रॉलर मूल रूप से वेबसाइटों के माध्यम से यात्रा करके जानकारी का पता लगाने के लिए डिज़ाइन किए गए हैं। इस तरह, वे उस जानकारी का पता लगाते हैं जिसे खोज इंजन द्वारा खोज परिणामों में प्रदर्शित करने के लिए अनुक्रमित किया जा सकता है।
क्या वेब क्रॉलर रोबोट हैं?
सॉफ़्टवेयर प्रौद्योगिकी के दृष्टिकोण से, क्रॉलर और रोबोट दोनों समान हैं। दोनों को ऑटो-प्रोसेस तरीकों से निष्पादित किया जाता है और दोनों को डेटा एकत्र करने और विश्लेषण करने के लिए प्रोग्राम किया गया है। अत: इनके कार्य प्रसंस्करण और इनके प्रयोजनों को देखकर यह कहा जा सकता है कि दोनों रोबोट हैं।
About The Author

Biswajit
Hi! Friends I am BISWAJIT, Founder & Author of 'DIGIPOLE HINDI'. This site is carried a lot of valuable Digital Marketing related Information such as Affiliate Marketing, Blogging, Make Money Online, Seo, Technology, Blogging Tools, etc. in the form of articles. I hope you will be able to get enough valuable information from this site and will enjoy it. Thank You.


